|
|
3 years ago | |
|---|---|---|
| images | 3 years ago | |
| .gitignore | 3 years ago | |
| README.md | 3 years ago | |
README.md
Hacklahoma AI Image Workshop (Fall 2023)
Launching a Stable Diffusion Instance on Cloud
Go to Google Cloud (or any other cloud provider), and open console. Trial $300 Google Cloud credits.
Since Google Cloud seems to be very scarce on GPUs, I will use RunPod in my demo today.
Create a VM with a GPU, at least 15GB RAM, and 30GB disk. Connect to SSH, install git, and clone this Automatic1111 (A1111) repository.
First cd in to the cloned directory and edit webui-user.sh for remote access:
$ cd stable-diffusion-webui
$ nano webui-user.sh
Add the following to COMMANDLINE_ARGS
--device-id=0 --no-half-vae --xformers --share
and exit nano with Ctrl+X saving the changes.
Now we are ready to launch A1111 with:
$ bash ./webui-user.sh
You should see a link like https://xxxxxxxxxxxxxxxx.gradio.live after the webui finishes launching. Warning, do NOT share the public link, others can abuse you instance and increase your bill.
Model Downloads
Popular Base Models:
SDXL1.0: https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors
SD1.5: https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/v1-5-pruned-emaonly.safetensors
DreamShaper8: https://civitai.com/api/download/models/128713
LoRA Models: CivitAI
Place downloaded models in appropriate sub-directories under stable-diffusion-webui/models.
Some technical background on the latent space of an image model:
Start Generating
Image Dimensions (Resolution)
As different models are trained on different image resolutions, it is best to use the training image resolution for generations. For SD1.5 use 512x512 and for SDXL1.0 use 1024x1024. You can slightly vary one of the dimensions without significant issues.
text2img generation
text2img can be thought of as generating visual content based on textual descriptions. Popular models include DALL-E, Midjourney, and Stable Diffusion. Stable Diffusion (such as SD1.5 and SDXL1.0) are open and gives us more control on the image generation process. A1111 starts with the text2img upon launch.
You can enter both a (positive) prompt and a negative prompt. For example:
Prompt:
cute cat, 4k ultra hd, highly detailed
Negative Prompt:
orange cat
img2img generation
img2img refers to the transformation of one image into another, typically maintaining the same content but changing the style or other visual attributes. A1111 has a img2img tab where you can try this. You can also suppliment the generation with a text prompt.
Inpaint
Inpainting is a technique to make small modification or fix small defects on an image. A1111 has an inpaint tab under the img2img tab.
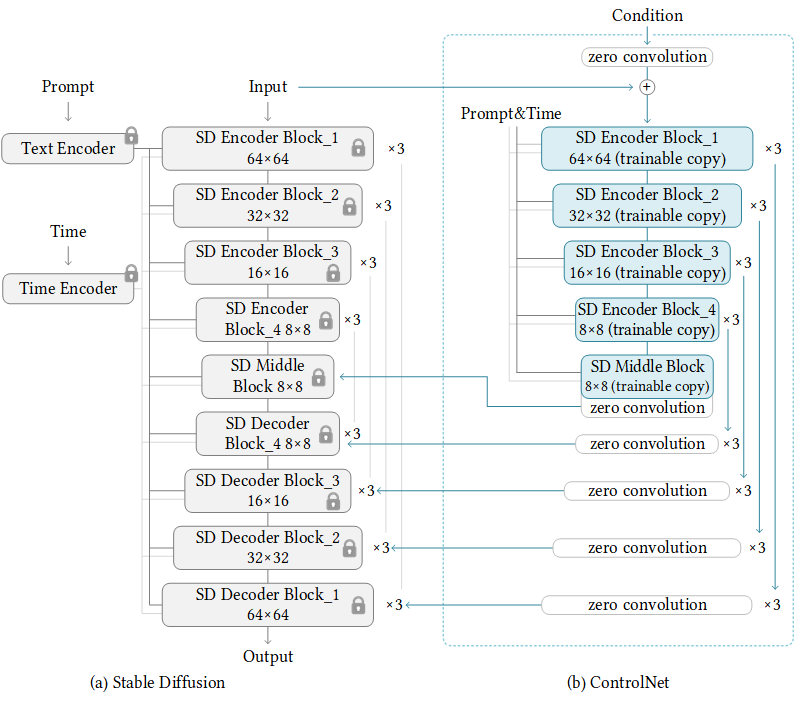
ControlNet (+Stable Diffusion)
ControlNet is a neural network structure to control diffusion models by adding extra conditions. Install extension for A1111: sd-webui-controlnet
Some technical background: